
简介
ECC 是“Error checking and Correction”的简写,中文名称是“错误检查和纠正”,是一种对传输数据的错误检测和修正的算法。
在数字电路中,最小的数据单位就是叫“比特(bit)”,也叫数据“位”,“比特”也是内存中的最小单位,它是通过“1”和“0”表示数据高、低电平信号的。空间中的无线电磁干扰、电路噪声会导致内存与CPU在进行数据交互的时候发生比特翻转(“0”变为“1”,“1”变为“0”)。

若某一位存储出了错误,就会使其中存储的相应数据发生改变而导致应用程序发生错误。大多数内存错误可通过重启解决,重启后内存里的数据被重新写入一遍。对于某些服务器来说,宕机一次带来的损失是巨大的,因此服务器往往会使用稳定性更高的ECC内存,这种内存回以主动发现数据传输过程中出现的错误,并将错误纠正。
对数据的校验常用的有奇偶校验、CRC校验等,而在NAND Flash处理中,一般使用一种比较专用的校验——ECC。ECC能纠正单比特错误和检测双比特错误,而且计算速度很快,但对1比特以上的错误无法纠正,对2比特以上的错误不保证能检测。
最简单的措施(三模冗余设计)
最简单的方法是在传输过程中,一组数据传输三遍。如果某组数据发生错误,通过对比其余两组数据,以其中相同的那两个为准,可定位错误的位置并纠正(只针对三组数据同一位置只有一个错误的情况,同时发生两个错误且同时位于同一位置的概率很低)。

如果三组数据同一位置都发生了比特翻转,在纠错的过程中就会把错误的数据当成正确的数据,导致数据出错。

但同时发生两个错误且同时位于同一位置的概率很低,这种方法最大的缺点在于浪费带宽,所有户数中只有1/3是有效的。

为了减少纠错码的占比,又能纠正错误,奇偶校验法被提出。
采用专业的说法,该方法称为三模冗余设计
三模冗余系统简称TMR(Triple Modular Redundancy),是最常用的一种容错设计技术.三个模块同时执行相同的操作,以多数相同的输出作为表决系统的正确输出,通常称为三取二.三个模块中只要不同时出现两个相同的错误,就能掩蔽掉故障模块的错误,保证系统正确的输出.由于三个模块是互相独立的,两个模块同时出现错误是极小概率事件,故可以大大提高系统的可信性。
基于SRAM的现场可编程门阵列(Field Programmable Gate Array,FPGA)对于带电粒子的辐射特别敏感,尤其是近年来高密度集成芯片的出现,电路容量增大、操作电压降低使得它们在辐射环境下的可靠性降低。其中软故障是主要的故障,它是由粒子和PN结相互作用引起的一种暂态故障,软故障对在基于SRAM的FPGA上实现的电路具有特别严重的影响。由于三模冗余技术简单性以及高可靠性,它是一个被广泛使用的针对于FPGA上的单粒子翻转(Single-Event Upset,SEU)的容错技术。

其优缺点如下:
(1) 不能对出错的单元进行修复。当三个单元中的一个单元出错后,它只是将错误通过多数表决器屏蔽,但是错误单元模块仍然存在。而且一般的TMR 也不能对错误进行检测和定位,以便系统进行修复。如果出现的错误得不到及时修复,那么当再次出现错误时TMR 将失效。
(2)普通TMR 资源开销大,资源利用率低。普通TMR 是对整个设计或者较大的模块进行三模冗余,粒度比较大,它的资源开销相比原始电路增大300%。对整个电路或者模块实现TMR,会造成资源浪费。
(3)由于电路的倍增使得功耗增大,而且由于表决器的存在以及其他一些额外的布线使得速度降低。
(4)表决器本身也可能出错,而一般的TMR 的表决器没有自检错能力,也不具备抗辐射能力。
(5)当采用三模冗余的电路驱动没有采用冗余电路时,需要一个表决器将三个信号合为一个信号。当没有采用冗余的电路驱动采用三模冗余电路时需要通过额外的布线将一路信号扩展成为三路信号。因为逻辑电路和布线资源都对SEU 敏感,所以这样的结果会降低系统可靠性。
奇偶校验码(parity check)
二级制数只有0和1,在数据开头增加一位“纠错码”,然后数出原始数据中1的个数。比如一个字节中存储了某一数值,数其中“1”的个数:若“1”为偶数个,纠错码定义为0。

若“1”为奇数个,纠错码定义为1,把总数据的1的个数填补成偶数。

所以接收方接收到数据后,如果数据中“1”的个数是偶数个,则数据没有错误。如果是奇数个,则数据发生了错误,因此需要重新传输新数据。当纠错码自己发生了比特翻转,仍能够检测出数据发生了错误。这是因为奇偶校验不是用一个数据去保护其他数据,而是通过1个数据政变整组数据的奇偶性,纠错码本身就存在于这组数据中。
但奇偶校验存在不足:当内存查到某个数据位有错误时,却并不一定能确定在哪一个位,也就不一定能修正错误,所以带有奇偶校验的内存的主要功能仅仅是“发现错误”,并不能纠正部分简单的错误。而且,如果同时有两个位发生比特翻转,“1”的总个数还是偶数,这种情况便检测不出数据是否发生错误。针对奇偶校验码的缺陷,理查德·卫斯里·汉明在其基础上发明了汉明码。
汉明码
汉明码的思想
这种纠错的基本思想是如何多次使用奇偶校验来二分查找出错误所在。
汉明码基本原理
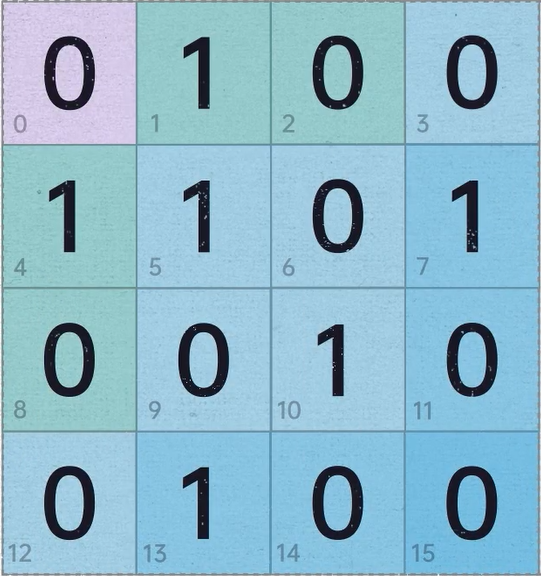
汉明码能用很少的纠错码对大量的数据进行错误的查找和纠正,以16bit数据为例:

其中,4位数据为纠错码,11位数据为有效数据(第0位为全局的奇偶校验位),这就是所说的(15,11)汉明码。
1号纠错码用来对2、4列的数据进行奇偶校验:

2号纠错码用来对3、4列的数据进行奇偶校验:

4号纠错码用来对2、4行的数据进行奇偶校验:

8号纠错码用来对3、4行的数据进行奇偶校验:

汉明码基本纠错原理如下所示:
<iframe width="50%" height="100%"
src="https://cloudpicture-1313887899.cos.ap-chongqing.myqcloud.com/blog_picture/202210102009260.mp4"
allowfullscreen></iframe>对于第0位数据,它是不在四位纠错码的纠错范围内的,它的错误与否不会影响奇偶校验的结果。同样,让第0位数据不存储原始数据,作为对全局的奇偶校验码。这样的好处是能够规避掉0号位无法保护的问题,又能检验出全局是否存在数据错误(只存在一个错误的前提下)。
举例
数据中有一个bit发生翻转,找出错误位置

答案为:

多个数据发生错误的情况
假设16bit数据中有两个bit发生翻转,
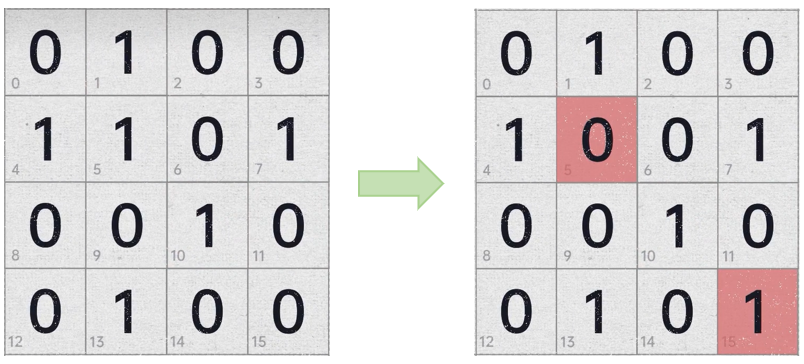
可通过汉明码基本原理找到错误的bit位为第10位

但是,分析第0位又得知,全部共有偶数个“1”,说明全局没有数据错误。

二者结论相矛盾,说明发生了两个错误。虽然没有办法定位错误数据的位置,但知道发生了2个数据错误的情况,可重新传输数据。
当存在3个数据错误时,汉明码无法解决。但是同时出现3个错误的向能性非常低,我们要考虑的应该是降低错误的发生概率,避免不要出现3个错误的情况。纠错码存在的意义是用尽可能少的数据去解决不回避免的错误。
汉明码的位置
汉明码本质上和二分法原理接近,所以校验位正好是在数据的一半。
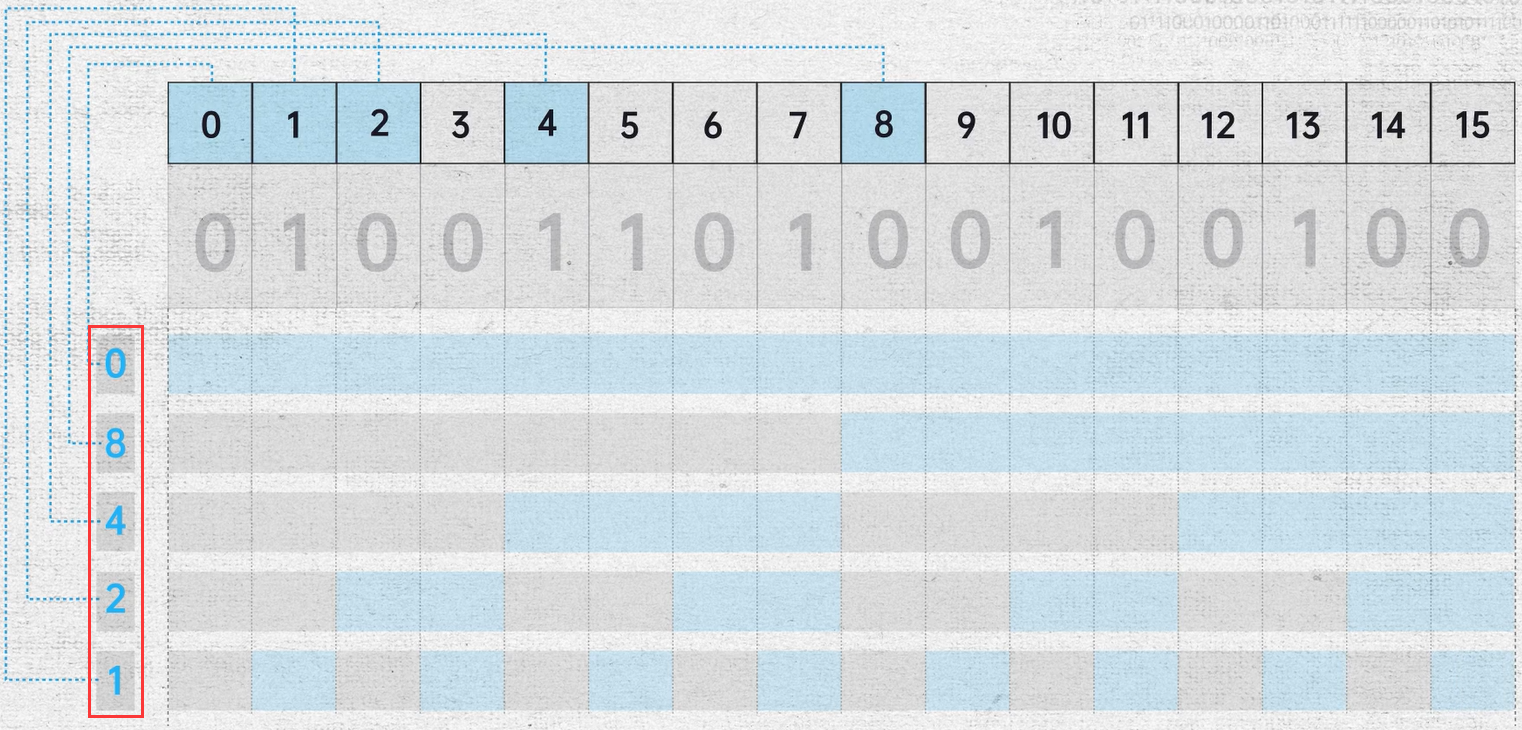
如果传输更多数据,只需要在每个2的第n次方上放置一位纠错码。而每多一位校验码,数据块大小就能翻倍,校验码占比就更小,换言之,信息率越高。

当然,数据越多时,出现两个或者更多错误的可能性也越大,汉明码便无法处理,所以实际操作时需要使用一个合适的数据块大小。随着纠错码的发展,这样的问题可以采用更先进的代码解决。

汉明码的硬件实现
汉明码的广泛应用不只是因为其能以较少的纠错码去检验较多数据位,还因为汉明码的硬件实现简单。
将上述16bit数据的位置角标改为对应进制数,可以发现:
1号纠错码的检验区域中(1号区域),所有位置角标的第1位数都是1,区域外其余角标第1位数均为0;
2号纠错码的检验区域中(2号区域),所有位置角标的第2位数都是1,区域外其余角标第2位数均为0;
4号纠错码的检验区域中(3号区域),所有位置角标的第3位数都是1,区域外其余角标第3位数均为0;
8号纠错码的检验区域中(4号区域),所有位置角标的第4位数都是1,区域外其余角标第4位数均为0;
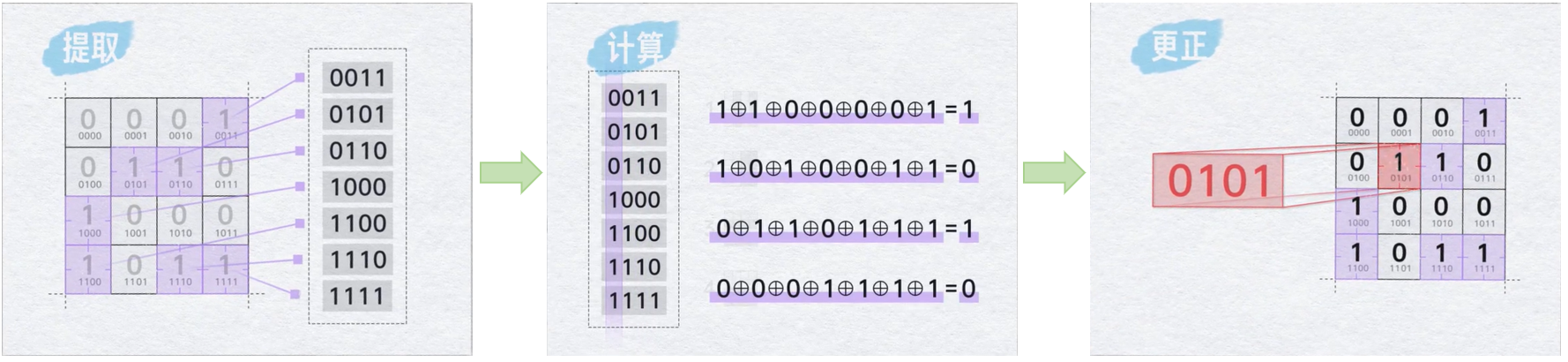
把所有包含1的位置数字全部提取出来,从上到下排列,可以发现,i(i = 1,2,3,4)号区域中的“1”在排列数字第 i 号位上为1,而其他区域的数据在这一位上刚好是0。这一列数即告诉了我们一号区域里有2个1,第2列数告诉了我们2号区域有4个1,第3列数告诉了我们3号区域有4个1,第4列数告诉我们4号区域也有4个1。

将每一列数的“0”和“1”六个数依次进行异或运算,如果1和0的个数是偶数,异或运算结果为0。由于四个区域的1的个数都是偶数。所以最终的结果就是0000。
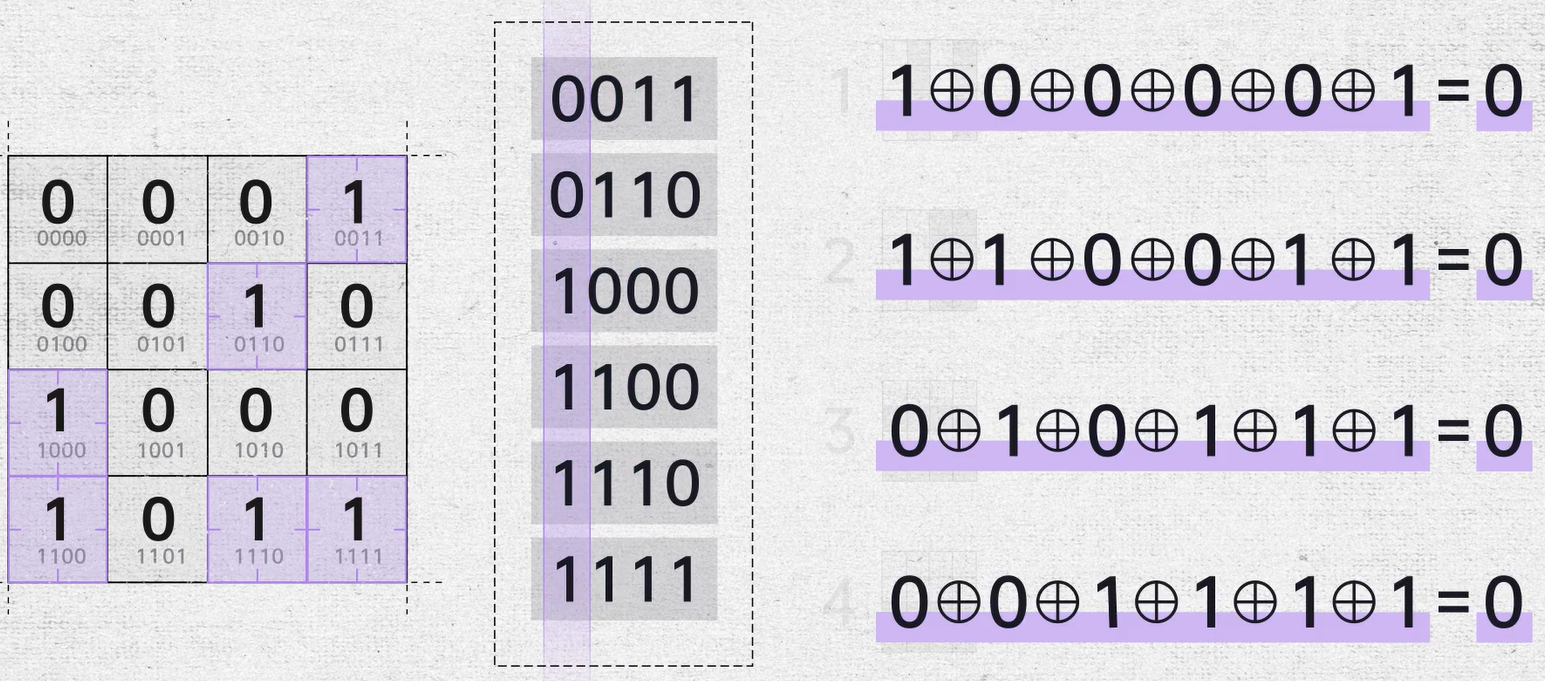
而这时候如果有任意一位0比特翻转成了1,这个数的角标就会直接穿插在6个数中间,相当于用0000去和它异或,结果会直接变成错误的数据位。我们一下就能找到是哪个数据发生了错误。
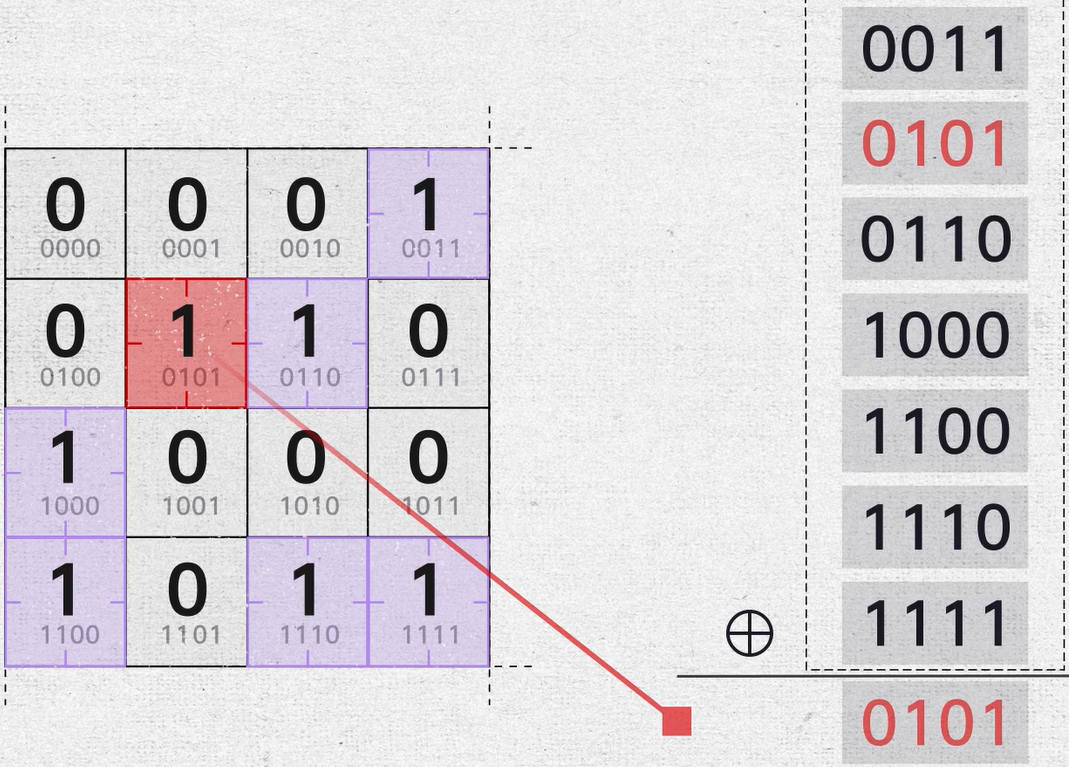
如果某个1变成0,这6个数会少一个,其实和增加一位是一样的,根据异或的性质,结果仍是错误的数据位。

所以,汉明码的纠错不需要一步一步地演算推理,只需要提取出所有1的位置,把它们的位置全部按照按顺序做一次异或运算,就可以直接定位错误的位置并更正。
Reference
【硬件科普】ECC内存是如何发现错误并纠正的?_哔哩哔哩_bilibili
【官方双语】汉明码Pa■t1,如何克服噪■_哔哩哔哩_bilibili









