
1. AHB-SRAM理想时序图
下面时序图是将SRAM 与总线连接的理想时序图,SRAM接收到总线的地址后,下一周期将数据返回给总线:
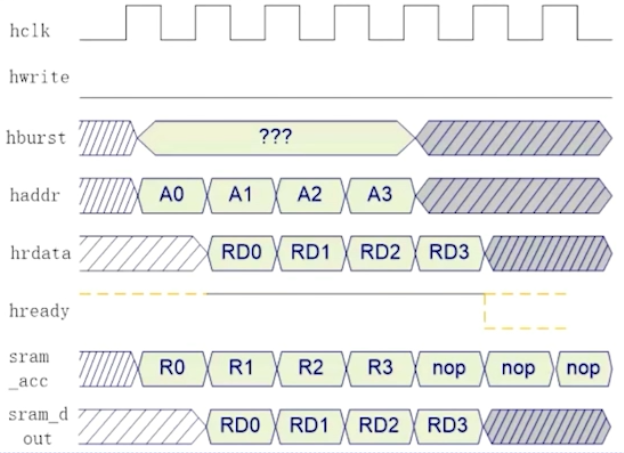
但是实际中要考虑延时,这样的设计是无法满足高速要求的:
- SRAM的clk→Q的delay本身比较大,可能会到1~2ns,根据SRAM的深度线性往上涨的。
- SRAM自身的setup比较大,addr的采样窗口比DFF大(大0.1~0.2ns左右)
- SRAM布局后可能是一个矩形,通常被放置在芯片外围,而控制模块,自动布局布线可能被放置在中间,二者距离较远,走线延时较大。
- Write part考虑: haddr/hwdata可能经过bus的MUX。
2. 高速AHB-SRAM设计
如何进行高速设计?
- 组合逻辑把bus上的haddr接给SRAM的addr;把SRAM的dout寄存1T后接给总线的hrdata。

每一笔 数据传输的开始,拉低hready来延迟1T接收SRAM,这样会有个副作用:拉低hready会导致haddr重复一周期,相应的SRAM输出data_out也会多一周期数据,在bus即将接收重复的数据时,不得不再拉低hready来避免接收重复的数据(如下图),这样每接收两个数据就得拉低hready,会影响bus效率。
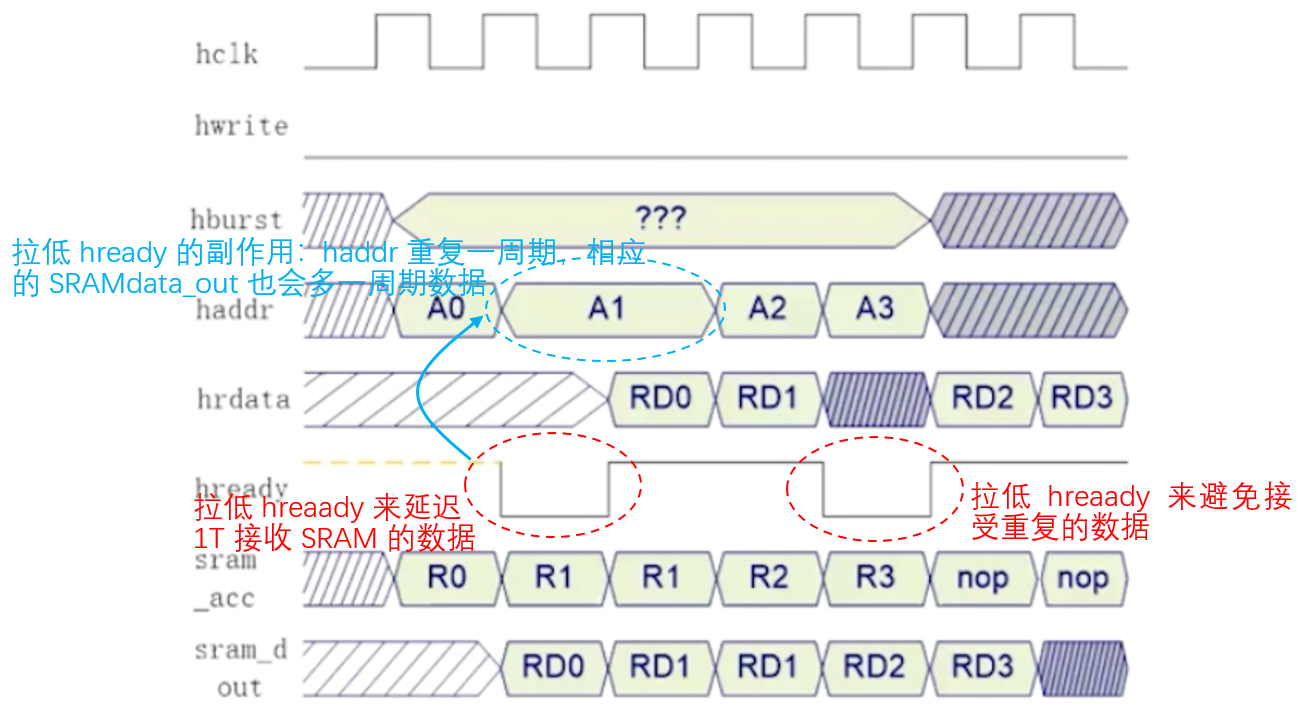
- 将总线的addr寄存1T给SRAM,将SRAM的data_out寄存1T给总线。

通过读取总线每笔传输的第一个地址,能够推测这一笔传输后面的地址,然后SRAM自己产生地址,即pre-fetch。所以要将总线的addr寄存1T给SRAM,将SRAM的data_out寄存1T给总线,每一笔传输的前面延迟2T即可,后面无需在拉低hready。
来自广东
